Détaillons l'architecture Ampere
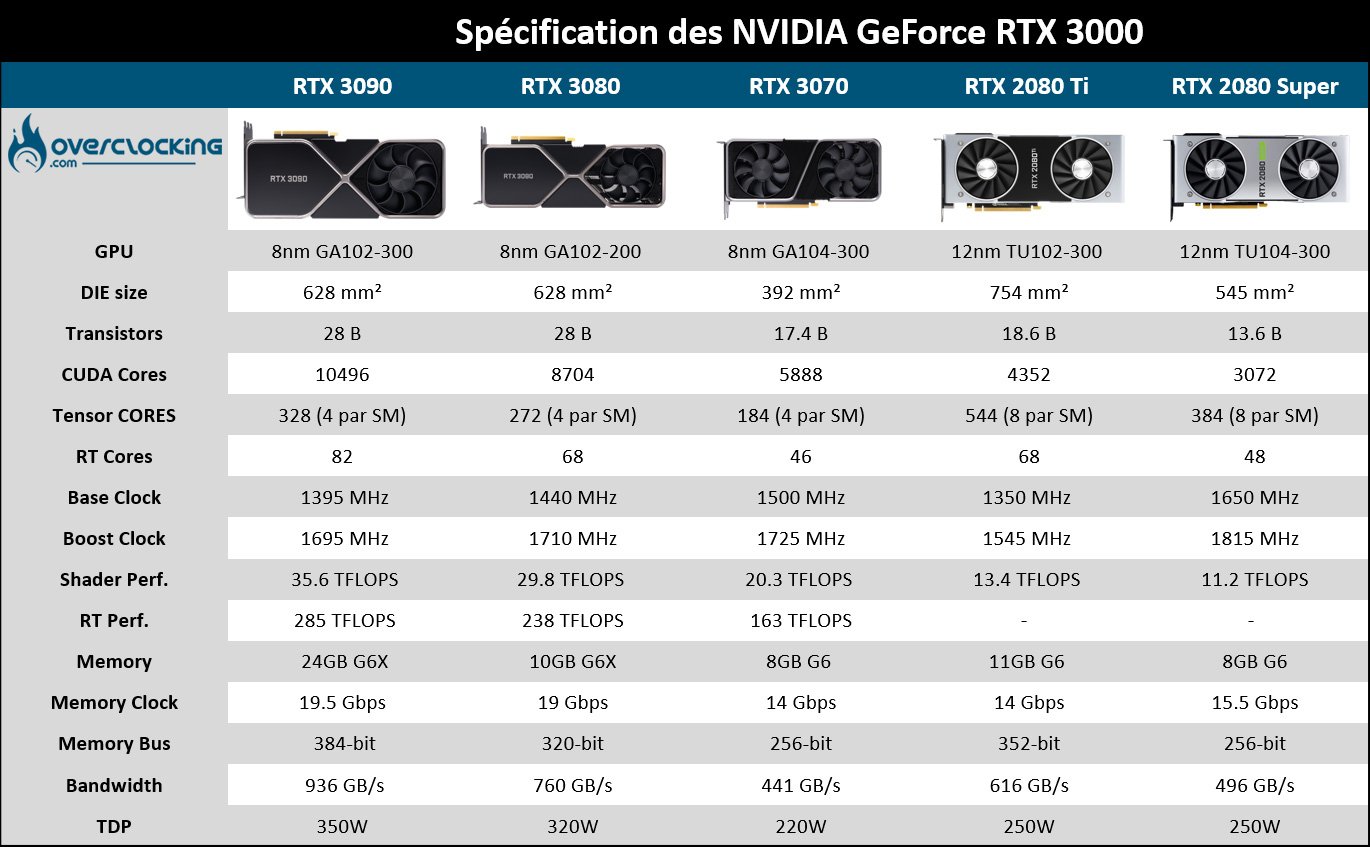
Et pour commencer, voici un tableau, presque complet, qui reprend les différentes caractéristiques que nous connaissons déjà sur les nouvelles cartes. Nous y avons ajouté volontairement la RTX 2080 Ti ainsi que la RTX 2080 Super afin que vous puissiez juger de l’évolution. Nous avons choisi de mettre ces deux modèles Turing en avant puisque NVIDIA compare ses nouvelles cartes justement avec eux.
Attardons-nous à présent sur les slides proposés par NVIDIA et à l’organisation interne au sein d’un SM (Streaming Multiprocessors). L’organisation y est différente par rapport à Turing et cette modification va permettre de doubler le nombre de FP32. Si vous observez bien la photo ci-dessous, vous pouvez apercevoir 4 blocs de 32 unites dans un SM. Dans chacun de ces blocs, on retrouve 16 FP32 ainsi que 16 FP32/INT32. Dans la pratique, soit le bloc peut gérer 32 instructions FP32 par cycle soit 16 instructions FP32 et 16 instructions INT32 par cycle. Si maintenant on regarde l’entièreté du SM, on dispose de 4 blocs permettant d’atteindre soit 128 instructions FP32 par cycle (32 x 4) soit 64 instructions FP32 (16 x 4) et 64 instructions INT32 par cycle (16 x 4).
C’est cela qui permet à Ampere de doubler le nombre de FP32 par rapport à Turing sans devoir augmenter la surface de la puce GPU. Le fait de doubler la vitesse de traitement du FP32 va améliorer les performances d’un grand nombre d’opération !

On peut également situer les 4 emplacements Tensor Core et celui du RT Core. Nous reviendrons par la suite sur leur rôle respectif.
Prenons à présent comme exemple la RTX 3080 afin de mettre en application ce dont nous avons parlé ci-dessus. Observez bien la photo ci-dessous.

Si l’on reparle des SM (Streaming Multiprocessors) dont nous avons détaillé la structure ci-dessus, ils sont au nombre de 68. Les 8704 CUDA Cores de la RTX 3080 se calcule en multipliant le nombre de SM (68) par les 128 instructions FP32 par cycle, ce qui nous donne un total de 8704.
Enfin, les Flops sont une unité de calcul utilisée pour les cartes graphiques. Pour être clair, il s’agit du nombre d’opérations pouvant être effectuées en une seconde sur des nombres à virgule flottante (source). Elle s’exprime la plus part du temps en TeraFLOPS (TFLOPS).
Pour obtenir la puissance de calcul d’une carte graphique, il suffit de réaliser ce calcul : nombre de CUDA Cores x Fréquence GPU (en GHz) / 1 000 x 2 = valeur (en TFLOPS).
Prenons l’exemple de la RTX 3080 : 8704 x 1.71 GHz : 1000 x 2 = 29,767 TFLOPS.
Les plus attentifs auront remarquer que les Tensor Cores sont eux au nombre de 68 x 4 par SM, c’est-à-dire 272. Mais quoi ? La RTX 2080 Ti en possédait 544 ! Cette RTX 3080 serait donc moins performante ? Non, et on vous explique ci-dessous pourquoi.
Quand au nombre de RT Core, il est de 68 comme sur la 2080 Ti, mais eux aussi, sont de nouvelle génération.
Les Tensor Cores de 3e génération :
Les Tensors Cores sont des unités dédiées aux calculs de l’IA (Deep Learning et Inférence) en usant de précisions de calculs faibles comme le FP16. Au contraire des unités shaders qui calculent en 2x par cycle (1 Addition et 1 Multiplication), les unités Tensors calculent sous forme de matrice 4×4, donc 16 additions et 16 multiplications par cycle.
NVIDIA a recourt au DLSS qui permet un gain en terme de FPS en remplaçant l’antialiasing TAA. L’idée est de permettre un affichage plus rapide tout en conservant une qualité de rendu quasiment identique. Lors de la conférence de presse, nous avons pu apprendre que le DLSS passait en version 2.1 et prenait en charge le 8K.


Comme nous vous le disions plus haut, sur une RTX 3080, ils sont moins nombreux (272) que sur la RTX 2080 Ti (544) mais ceux-ci évoluent et sont de 3e génération. Malgré cela, ils parviennent à doubler la puissance de calcul sur les matrices denses et de la quadrupler sur les matrices creuses. Une matrice dense contient peu de 0 et une matrice creuse beaucoup de 0.
Les RT Cores de 2e génération:
Les RT Core sont utilisés par l’API Ray Tracing, une solution pour l’éclairage, les reflets et les ombres réalistes. Chaque SM dispose d’un RT Core, donc 68 unités au total. Turing était la première architecture à le proposer en temps réel. Comme pour les Tensor Cores, les RT Cores évoluent aussi ! NVIDIA les annonce plus efficaces et surtout capables de réaliser des calculs plus rapidement.





