Cet article portera sur l’architecture vectorielle d’ATI/AMD qui a été employé depuis les Radeon HD 2000 jusqu’aux Radeon HD 6000. Il vous expliquera sa manière de fonctionner et les différences avec l’architecture dite scalaire utilisée par Nvidia.
Difficulté : Expert
Avant toute chose, il peut être bien de lire ce Quicky parlant de l’organisation des GPU. Cela vous permettra de comprendre beaucoup de choses pour la suite.
Vectoriel, Quezako ?
Basons-nous sur la première puce : la R600 de la HD 2900. Elle dispose de 320 processeurs de flux répartis en 5 blocs de 64 unités. L’architecture employée est le vectoriel 5D, plus connu sous l’abréviation VLIW5. VLIW veut dire « Very Long Instruction Word ». Comme son nom l’indique, le VLIW se destine à effectuer des instructions avec des données longues.

Vu que le registre vectoriel est d’une longueur de 64 bits, la Radeon HD 2900 (Tout comme ses successeurs) peut effectuer 64 éléments en parallèle par instruction. Mais un détail important : on a affaire a du 5D, donc cela veut dire qu’elle peut traiter, non pas une seule instruction de 64 éléments par cycle, mais 5 instructions. Ce qui fait que la R600 peut traiter 320 éléments par cycle.
Les unités de calcul des puces VLIW sont de type MIMD (Multiple Instruction Multiple Data), donc MIMD-5Way. Le MIMD signifie que l’architecture peut effectuer plusieurs instructions différentes en parallèle. Le contraire donc du SIMD (Single Instruction Multiple Data) qui se base sur un traitement d’une seule instruction par cycle qui effectue plusieurs données.
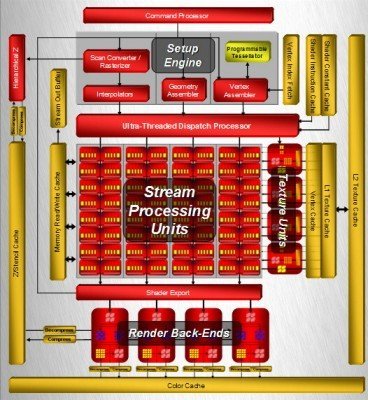
Des coeurs en grappe :
Nous allons aussi faire un point sur la réalité des architectures vectorielles, en particulier sur le nombre de processeurs de flux.
Pour la HD 2900, parler de 64×5 ou 320, c’est très différent. En effet, les 5 instructions ne peuvent pas être dépendantes l’une de l’autre. Alors que l’architecture scalaire de la GeForce 8800 Ultra va casser les instructions vectorielles en instructions scalaires (Ceci afin que chaque instructions puissent être la suite de la précédente), la HD 2900 va faire l’opération inverse et assembler toutes les opérations simples entre elles afin de remplir complètement les unités 5D. Si cela n’est pas possible sur une instruction, alors le bloc vec-5 ne sera pas utilisé à son potentiel maximal.
Ces unités étant de type VLIW, cela signifie que les instructions envoyées au GPU sont très longues et complexes. Cela apporte un gros inconvénient : cela réduit l’efficacité de la puce.
L’unité VLIW comme dit précédemment abrite 5 unités MIMD. Si on se réfère à la présentation de la HD2900 XT, l’unité VLIW abrite 5 FMA/INT, elles peuvent donc effectuer des opérations sur des nombres entiers 16 bits et 32 bits (INT), et sur des nombres décimaux 32 bits (FMA). L’une des 5 unités peut effectuer en plus des entiers et décimaux, des calculs spéciaux (sin, cos, exp, log, etc…).
Ce qui fait que la HD 2900 XT peut effectuer 320 opérations classiques (INT/FMA) ou 256 opérations classiques ET 64 opérations spéciales.
Plus dur à optimiser !
Mais voilà, le VLIW bien qu’efficace dans les jeux vidéo, présente de grosses lacunes dans d’autres activités comme le GPGPU. En effet, il est impossible de monopoliser toute une puce pour une activité, donc pour un calcul computing, la puce se voit de ne pas être employée à 100%.
Donc une HD 5870 qui peut atteindre 2.7 TFLOP a en réalité une efficacité moindre face aux 1.5 TFLOP d’une GeForce FERMI où grâce à son architecture scalaire se voit être employé intégralement.

ATI a cherché a bien exploité le vectoriel avec son API propriétaire : le CAL (Aussi nommé ATI Stream). Bien que sa programmation soit simple, il ne fut que peu utilisé au profil de CUDA qui s’est imposé plus rapidement grâce à des puces plus efficaces.
L’OpenCL de son côté est moins adapté pour du vectoriel, mais cependant plus employé que CAL, d’où les énormes efforts d’ATI pour adapter son architecture. Les HD 5800 ont résolus ce problème, mais il reste les limites du VLIW. Limites qu’AMD a cherché à compenser au mieux avec le VLIW4 apparu avec les Radeon HD 6900 qui ne se base plus sur du 5D, mais du 4D, permettant ainsi des instructions moins grandes.

Le vectoriel est mort, vive le scalaire !
Le vectoriel ayant atteint sa limite, AMD a définitivement mit à terme au VLIW pour passer au scalaire avec l’architecture GCN, avec les Radeon HD 7000. Et depuis, AMD est resté sur de l’architecture scalaire, laissant le vectoriel aux architectures passées.

Pour finir, voici une comparaison des GPU:
- Radeon HD 2900: 64 (5D) <=> GeForce 8800 GTX: 128 (1D)
- Radeon HD 3870: 64 (5D) <=> GeForce 9800 GTX: 128 (1D)
- Radeon HD 4870: 160 (5D) <=> GeForce GTX 280: 240 (1D)
- Radeon HD 5870: 320 (5D) <=> GeForce GTX 480: 480 (1D)
- Radeon HD 6870: 224 (5D) <=> GeForce GTX 560 Ti: 384 (1D)
- Radeon HD 6970: 384 (4D) <=> GeForce GTX 580: 512 (1D)
- Radeon HD 7970: 2048 (1D) <=> GeForce GTX 680: 1536 (1D)
- Radeon R9 290X: 2816 (1D) <=> GeForce GTX 780 Ti: 2880 (1D)
- Radeon R9 Fury X: 4096 (1D) <=> GeForce GTX 980 Ti: 3072 (1D)
- Radeon RX Vega 64: 4096 (1D) <=> GeForce GTX 1080 Ti: 3840 (1D)
Maintenant se pose la question : est-il correct de dire 320 coeurs pour une HD 2900 XT ? Y-a-t-il tromperie marketing ? Réponse ici.
Voilà vous savez quasiment tout sur les archi vectorielles maintenant.



Ouais c’est des cœurs pas aussi efficaces que des cœurs scalaires. Après ils pouvaient en mettre plus.
bin je suis largué mais bon je vais relire plusieurs fois…..
Pour résumer très grossièrement, les HD 2000 à 6000 (hormis les 6900) étaient en vectorielles 5 Way. Les coeurs étaient en « blocs de 5 ». Et pour qu’une instruction utilise bien la puissance des 5 coeurs d’un blocs, elle doit être vectorielle, sinon tout n’était pas utilisé.
Donc le vectoriel est performant sur les instructions qui en tirent bien parti (bcp plus de Gigaflops que les archi scalaires équivalentes) mais c’est difficile à exploiter à 100 %.
donc il aurai fallut plus de blocs ou c’était au max ou alors réduire la finess des blocs tout en aisséllant de trouvé un moyen d’exploité ceci au max ( à 100% ) si j’ai bien compris il faudrait mélangé le meilleur des deux technologies…si c’est possible?
En fait les archi « scalaires » c’est des blocs de 1. Donc Nvidia depuis les 8000 et AMD depuis les 7000 a arrêté ce design en bloc, pour avoir une archi plus exploitable.